Op deze website (en nog steeds hier te lezen) hebben we een bericht geplaatst dat we voor de grap helemaal hadden laten schrijven door kunstmatige intelligentie (AI). Het bericht zag er echt uit, had zelfs wat relevant lijkende informatie van het internet erbij gehaald en wat namen verzonnen die citaten leverden. Briljant, enerzijds, maar ook een beetje eng. Terecht maakte bijvoorbeeld het Letterenfonds zich zorgen over het feit dat de kunstmatige intelligentie zomaar die – boven elke twijfel verheven – instelling erbij had gehaald. De in het artikel aan het fonds toegeschreven woorden zijn dan ook nooit door dat fonds gebezigd.
Zulke dingen zijn dus mogelijk in AI. Met GPT 3 (Generalized Parsing Toolkit, waarmee het talige deel van de algoritmes wordt ontwikkeld, op niveau 3) kunnen we, als het over zelfrijdende auto’s zou gaan, bijna de handen van het stuur houden en toch veilig op de bestemming aankomen.
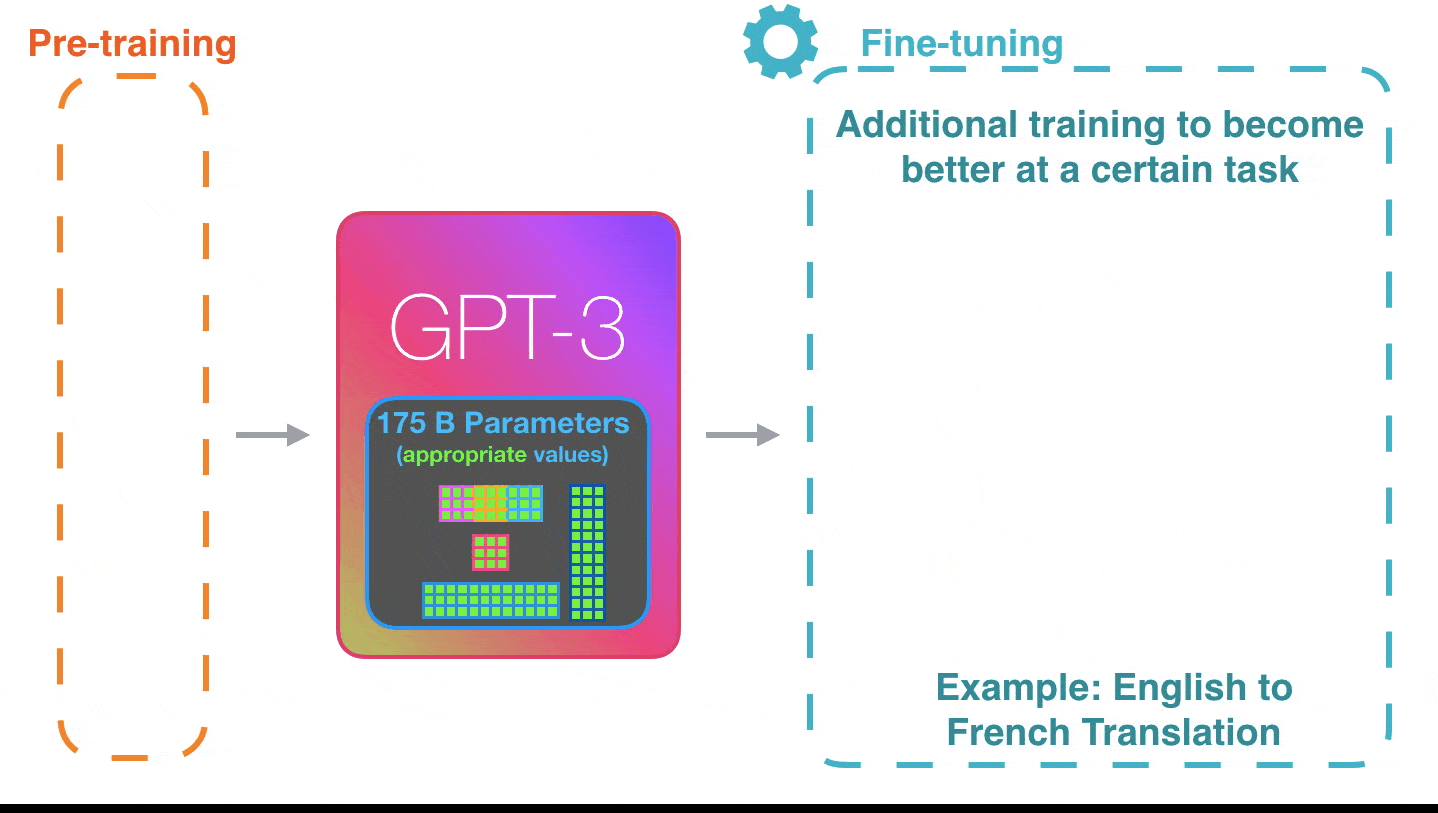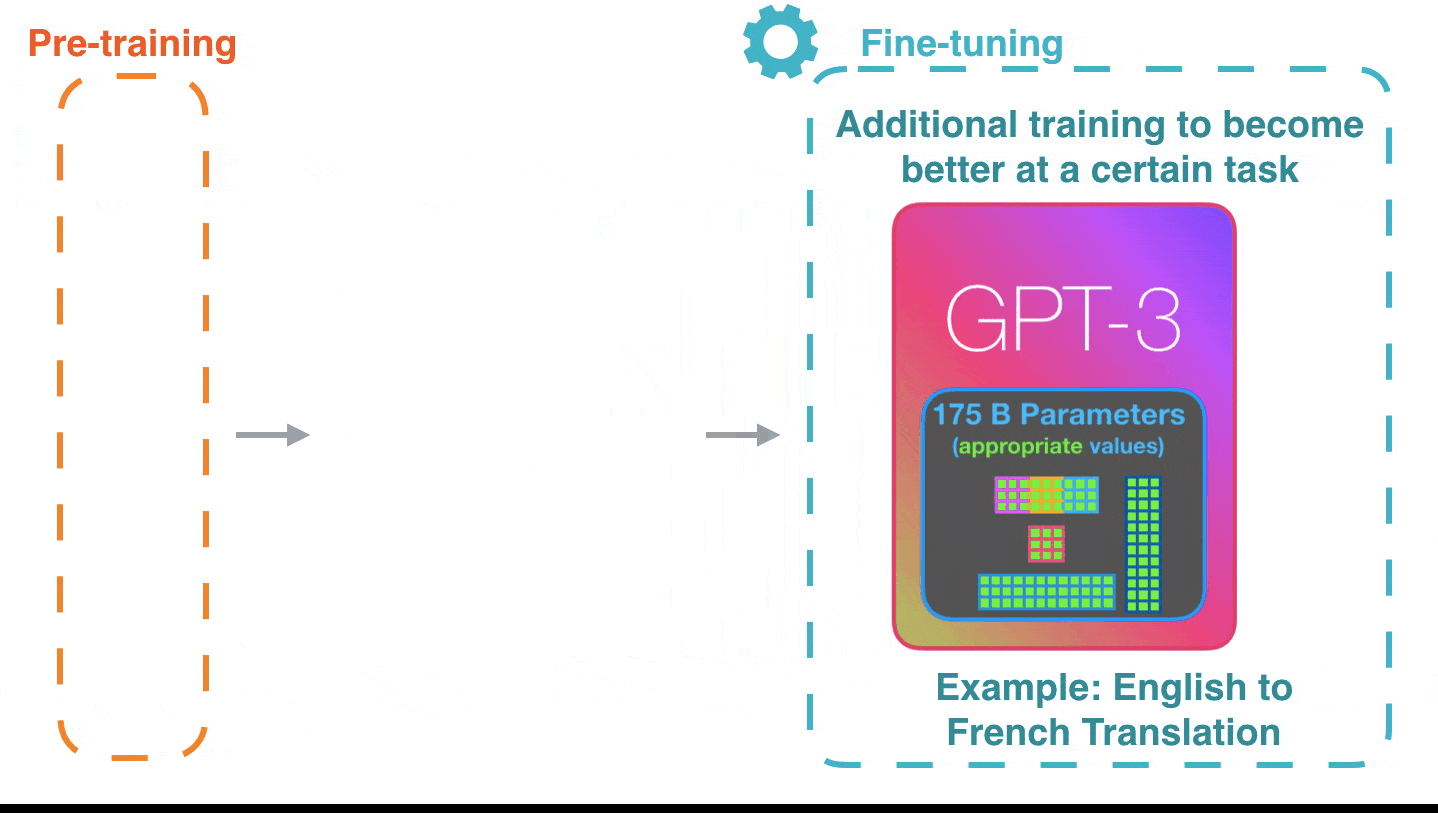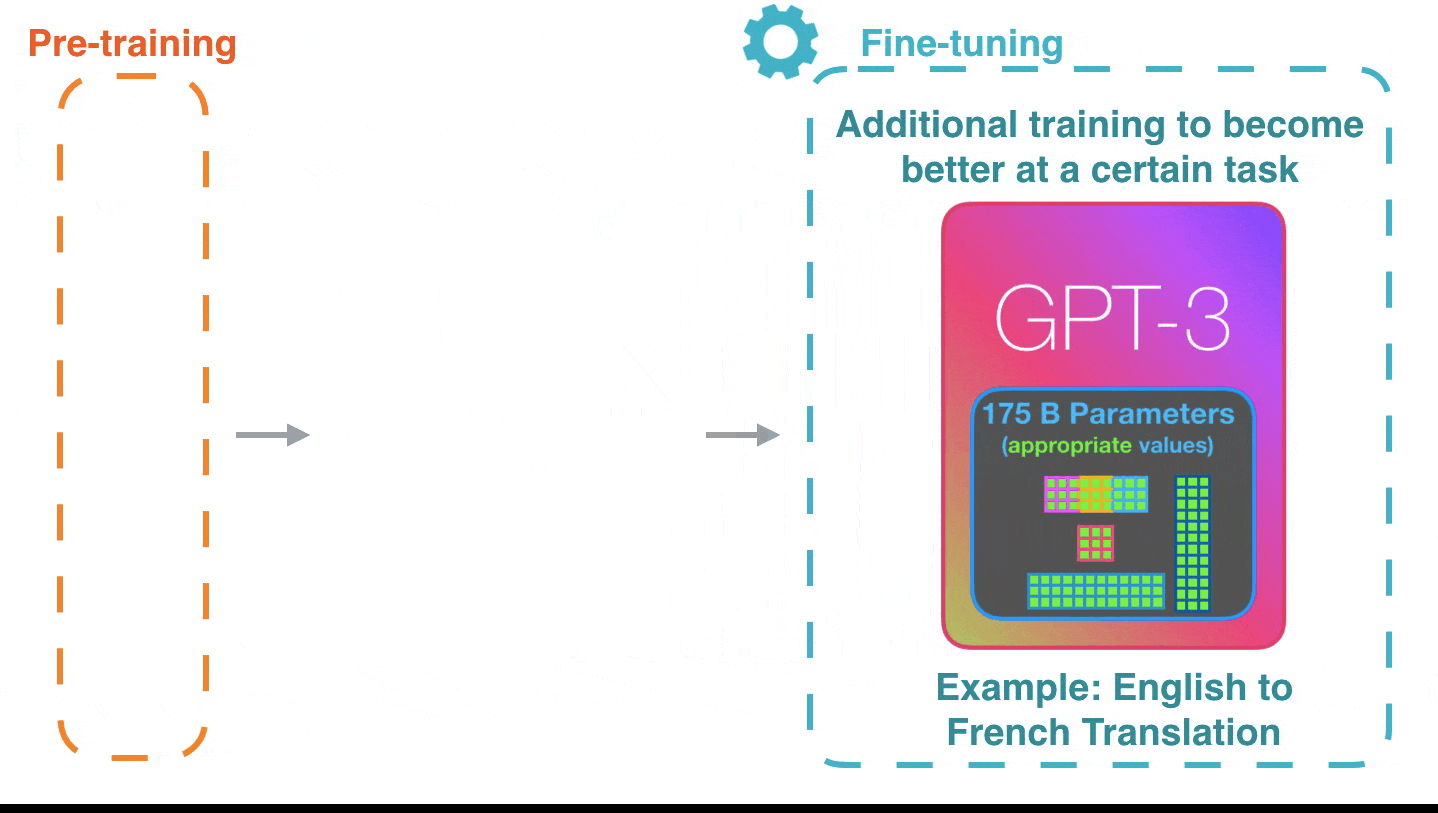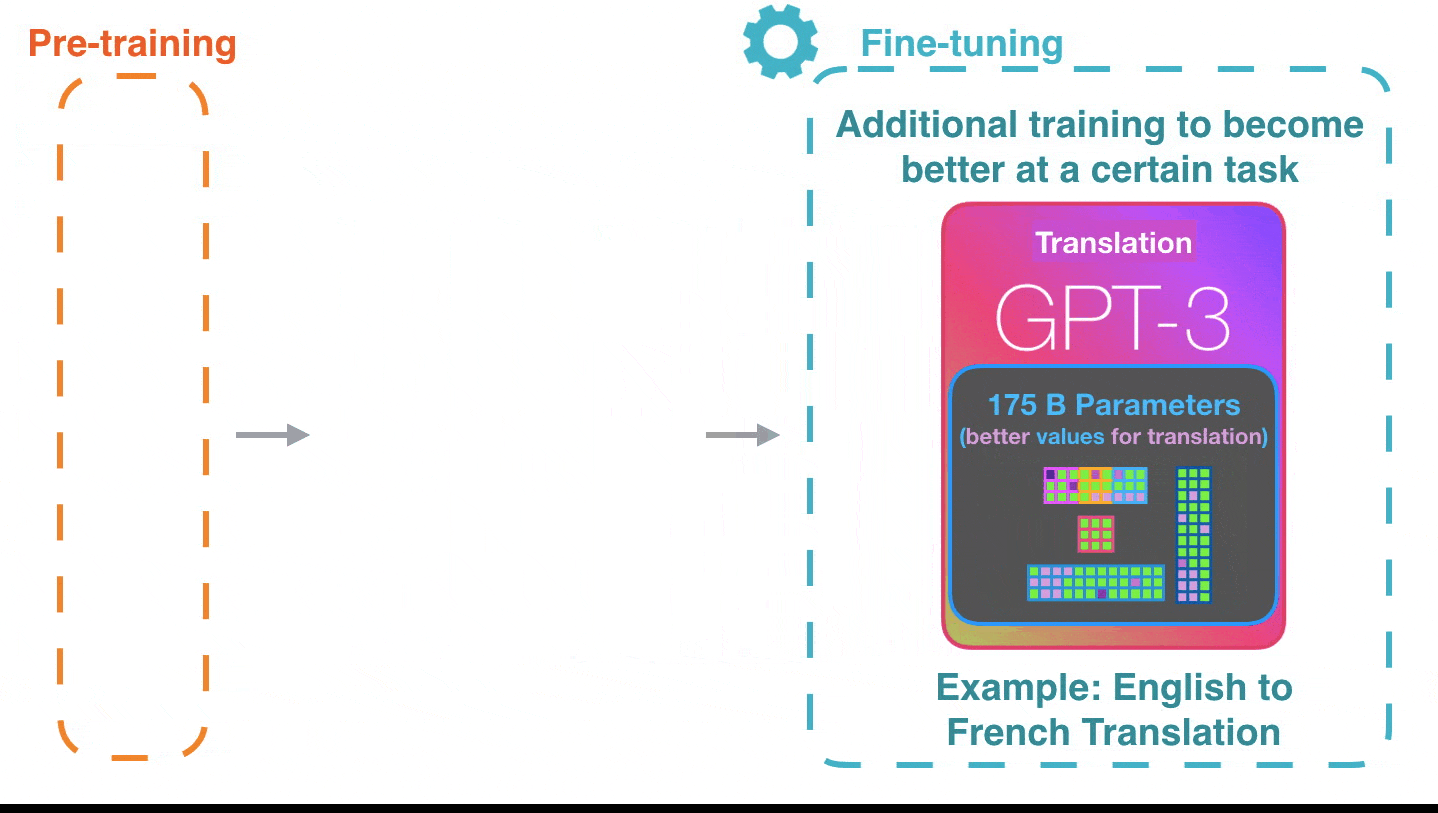
Muziek
Wat dit voor gevolgen heeft is moeilijk nu al in te schatten. Zo kan je met Open AI nu al muziek laten maken die soms best aardig te gebruiken is, al zou ik die nog niet willen draaien in de zelfrijdende tesla. Maar het moment lijkt niet ver meer dat het wel gaat kunnen.
Voor NBD Biblion, de bibliotheekdienst die bibliotheken helpt met het inkopen van boeken, is het moment al daar. Ook al kijken er nog wel mensen mee: het samenvatten en zelfs beoordelen van in te kopen boeken is nu in handen van een algoritme. Uitgevers leveren pdf’s van boeken aan, de AI scant die, vat de boel samen en geeft een score op trefwoorden. Objectief en neutraal, veel sneller dan voorheen en je kunt 700 menselijke recensenten op straat zetten met een e-mail.
Webinar
Vorige week was er een webinar over de ontwikkeling, mede ook om antwoord te geven op de vraag waarom zo ineens al die recensenten op straat stonden. Het webinar is zelf niet terug te zien, wel stuurde de organisatie een Q&A-verslag met antwoorden op de meeste vragen.
Het is vrij uitgebreid, maar ook een beetje kortaf, zeker als het gaat om de antwoorden op de vragen die door de deelnemers gesteld worden. Dat helpt bij de duidelijkheid, natuurlijk. Toch spreekt er heel erg uit dat NBD Biblion vooral vertrouwen vraagt van ‘het veld’, en dat alle eventualiteiten, zoals een algoritme dat opeens tot vooroordelen leidt, zijn afgedekt.
Gigabyte
Op de vraag van een deelnemer of NBD Biblion dan voorbeelden kon geven van hoe het proces werkte, was het antwoord tekenend: ‘Na tien jaar werk hebben we ongeveer 130 gig aan modellen en er zijn honderden verschillende processen. Een simpele uitleg doet geen recht aan de werkelijkheid. Alle informatie die gebruikt wordt voor de Al-tekst komt uit het boek.’
Dat is een helder antwoord, waar we dan maar op zullen vertrouwen.



